Claude Code History: Where It Is Stored and How to Find, Back Up & Resume It
Where does Claude Code store your conversations?
Claude Code stores all conversation history locally on your machine in ~/.claude/projects/. Each project gets its own subdirectory (based on the absolute path), and each conversation is saved as a JSONL file with a unique session ID.
The native tools to access this history are straightforward:
/history- List recent sessions inside an active Claude Code sessionclaude -c- Resume the most recent conversation for the current projectclaude -r SESSION_ID- Resume a specific conversation by its ID
You can find full details on these commands in the official Claude Code documentation. They work, but they have real limitations once you start using Claude Code seriously across multiple projects.
The problem with native Claude Code history
Native history was designed for simple use: resume your last conversation or list recent sessions. Once you go beyond that, things get frustrating fast:
- No search. You cannot search for "that authentication discussion from last week" across your conversations. You would need to grep through raw JSONL files manually.
- No cross-project access. History is locked to the project directory where the conversation started. Want to find a conversation from another project? Navigate there first.
- No visual overview. There is no way to see all your conversations at a glance, organized by project or date.
- No content preview. You see session IDs and timestamps, but not what the conversation was actually about.
- No filtering. Cannot filter by project, date range, or conversation content.
If you use Claude Code on one project occasionally, this is fine. But if you work across multiple projects daily and rely on Claude Code as your main development tool, you need something better.
Full conversation history with CodeAgentSwarm
CodeAgentSwarm wraps Claude Code with a complete history system that solves every limitation listed above. Every conversation, across every terminal, across every project, is automatically stored, searchable and resumable.
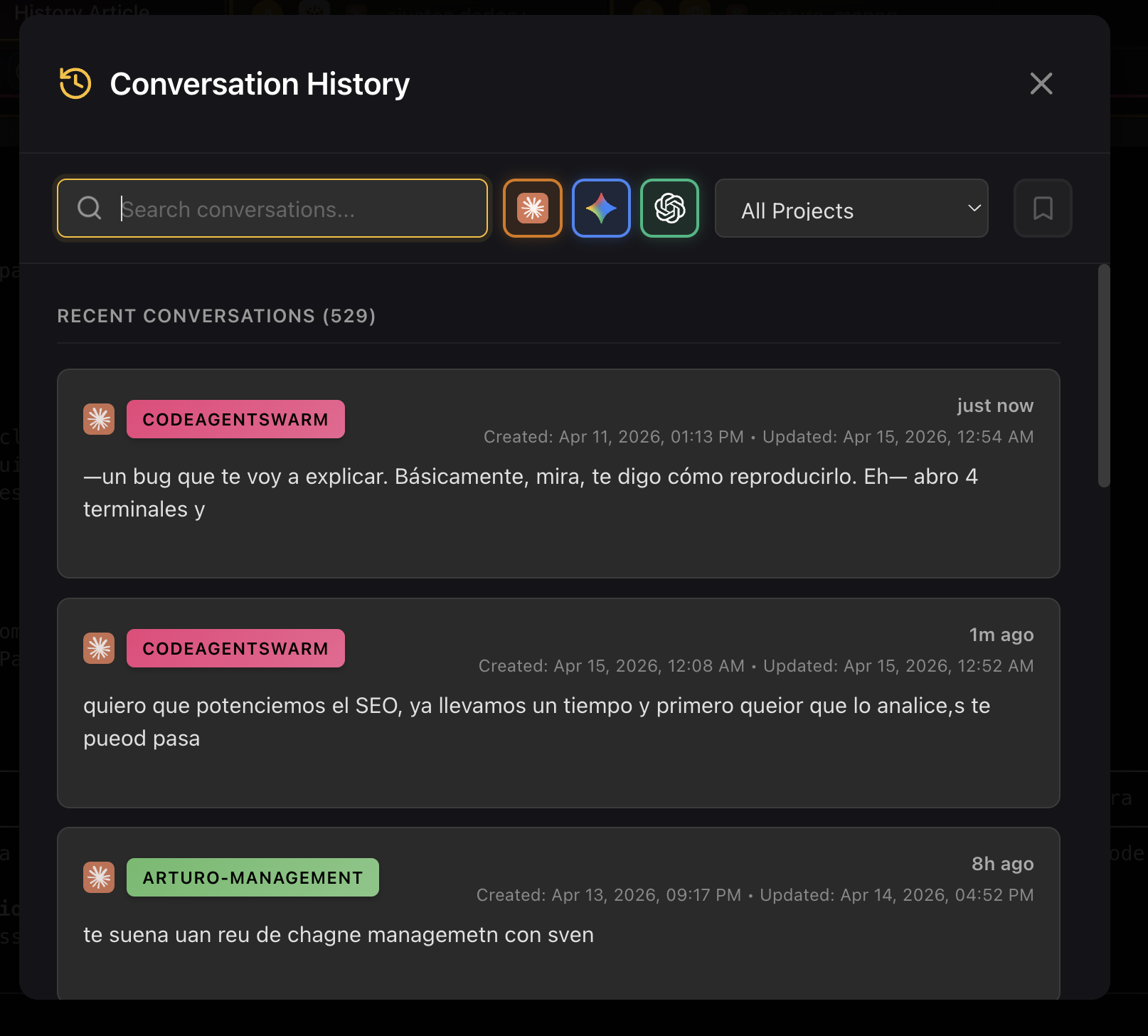
Search any conversation instantly
Type what you remember - a module name, a bug description, a technology - and CodeAgentSwarm searches across all your conversations from all projects. Results show the conversation title, project, date and the matching messages so you know immediately if it is the right one.
No more grepping through JSONL files. No more guessing which project a conversation belongs to.
Visual history organized by project
Instead of a flat list of session IDs, you see all your conversations organized by project and date. Each project has its own color, so scanning through history is fast even when you have dozens of conversations.
- Conversations grouped by project with color coding
- Most recent conversations first, with dates visible
- Conversation chains grouped together (continuations of the same thread)
- One-click access from any terminal
Resume with one click
Found the conversation you need? Click on it and CodeAgentSwarm opens a new terminal with all the previous context loaded. Claude remembers everything: the code you discussed, the decisions you made, the explanations you gave. No cd to the right directory, no claude -r with a session ID. Just click and keep working.
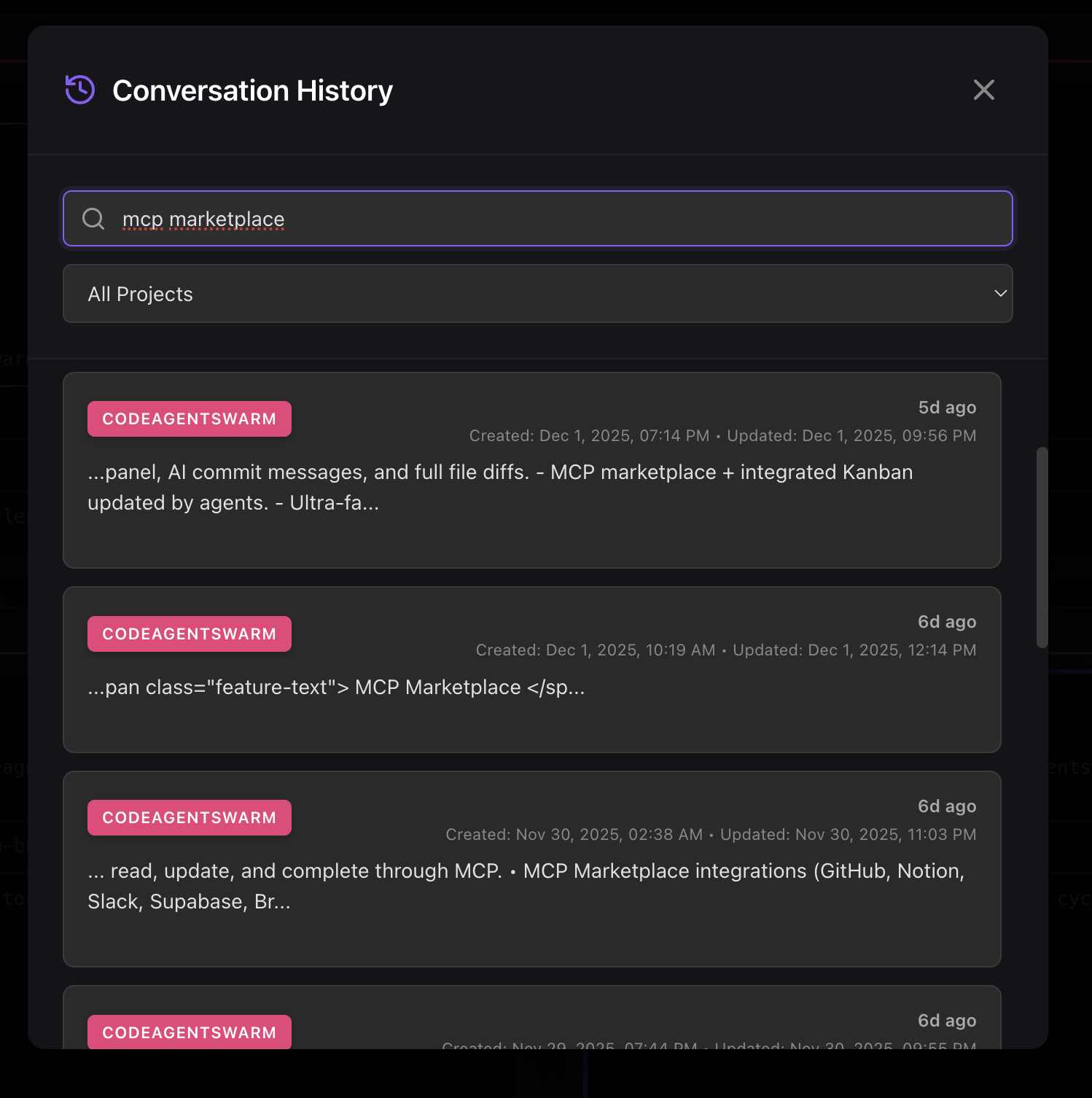
Cross-project search
This is the feature that makes the biggest difference for developers working on multiple projects. Search for "database migration" and see results from your backend project, your microservice, and that side project where you set up Knex. All in one view, no directory switching.
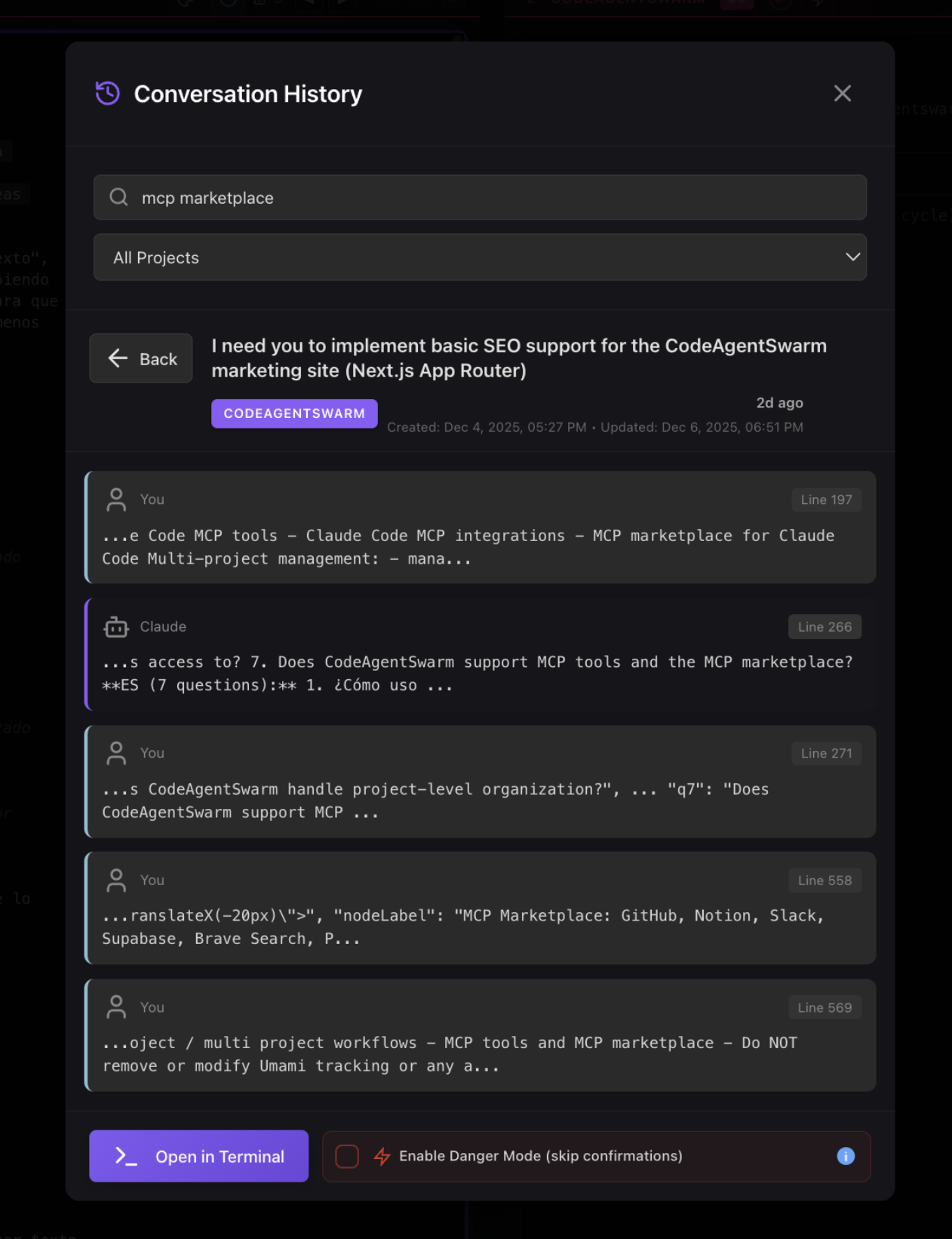
Resume mode when opening a project
When you open a project in CodeAgentSwarm, you can choose resume mode. Instead of starting a blank conversation, you see all your recent conversations from that project and pick which one to continue. Search within them to find the exact conversation thread you need.
For a detailed walkthrough of all these features, see our dedicated guide: Using conversation history in CodeAgentSwarm.
Why conversation history changes how you work with Claude Code
This is not about convenience. It is about fundamentally changing how productive you can be with Claude Code:
- Stop re-explaining modules. You spent 15 minutes explaining your auth system to Claude last Tuesday. With history, you resume that conversation instead of explaining it again from scratch.
- Keep decisions consistent. Architecture decisions accumulate across conversations. Without history, you risk contradicting a decision you made three days ago because you forgot.
- Save tokens. Every time you re-explain context, you are burning tokens and time. Resuming a conversation with existing context is cheaper and faster.
- Work across multiple projects confidently. When you can search and resume any conversation from any project, switching between projects stops being a context-switching nightmare.
- Never lose a solution. That clever fix you came up with at 11pm? It is in your history. Search for it, find it, reuse it.
Tips for getting more value from your history
Regardless of which tools you use, these habits make your conversation history much more useful:
- Start conversations with specific context. "Fix the JWT token expiration bug in the auth middleware" is much easier to find later than "Fix the login bug".
- One topic per conversation. Mixing unrelated tasks makes it harder to find and resume specific work later.
- Resume instead of re-explain. If you spent time explaining a module to Claude, resume that conversation next time. The context is already there.
- Use CLAUDE.md for permanent context. Put architecture decisions and conventions in CLAUDE.md as "permanent memory". Use conversation history as "working memory" for specific tasks.
If you work with multiple Claude Code terminals in parallel, conversation history becomes even more valuable. Check our guide on running multiple Claude Code terminals in parallel.
FAQ
Claude Code stores all conversations locally in ~/.claude/projects/ on your machine. Each project gets its own subdirectory, and conversations are saved as JSONL files with unique session IDs.
Yes. Every conversation is automatically saved. You do not need to enable anything - history is on by default.
With native tools, use /history inside a session or browse files in ~/.claude/projects/. With CodeAgentSwarm, you get full-text search across all conversations and all projects with one click resume.
Use "claude -c" to continue your most recent conversation, or "claude -r SESSION_ID" for a specific session. In CodeAgentSwarm, just click on any conversation in the history view to resume it.
Native Claude Code has no built-in search. You would need to grep through JSONL files manually. CodeAgentSwarm provides instant full-text search across all conversations, all projects, with message preview and filtering.
Native history is tied to each project directory separately. You need to navigate to the project first. CodeAgentSwarm provides cross-project search and resume from any terminal.
Copy the ~/.claude/projects/ directory to your backup location. All conversations are local files, so standard backup methods work.
Yes. Copy ~/.claude/ from the old machine to the new one. Note that paths are absolute, so it works best when your directory structure matches.
No. Each conversation uses a few hundred KB to a few MB. Even heavy users rarely exceed 500MB total.
/history lists recent sessions and their IDs inside an active session. "claude -c" starts Claude Code and automatically resumes the most recent conversation for the current project.
Try managing your Claude Code history with CodeAgentSwarm. Search any conversation, filter by project, and resume in one click.
Try CodeAgentSwarm